



Са повећањем доступности интернета експоненцијално расте количина података која се производи. Почетком 2020. процењено је да дигитални универзум садржи 44 зетабајта података који се креирају путем интернета, друштвених мрежа, интернета ствари, а са развојем 5G мобилне мреже овај раст ће бити све бржи.
Доступност све веће количине података не значи и да смо постали паметнији. Да би се то догодило, потребно је да интерпретирамо податке на прави начин. И последњих година се управо то дешава. Методе математике, статистике, инжењерских решења, од којих су многе присутне деценијама уназад, доживеле су свој процват кроз примене у анализи података, најпре у технолошким компанијама (Google за рангирање претраге, LinkedIn за предлог контаката итд.).
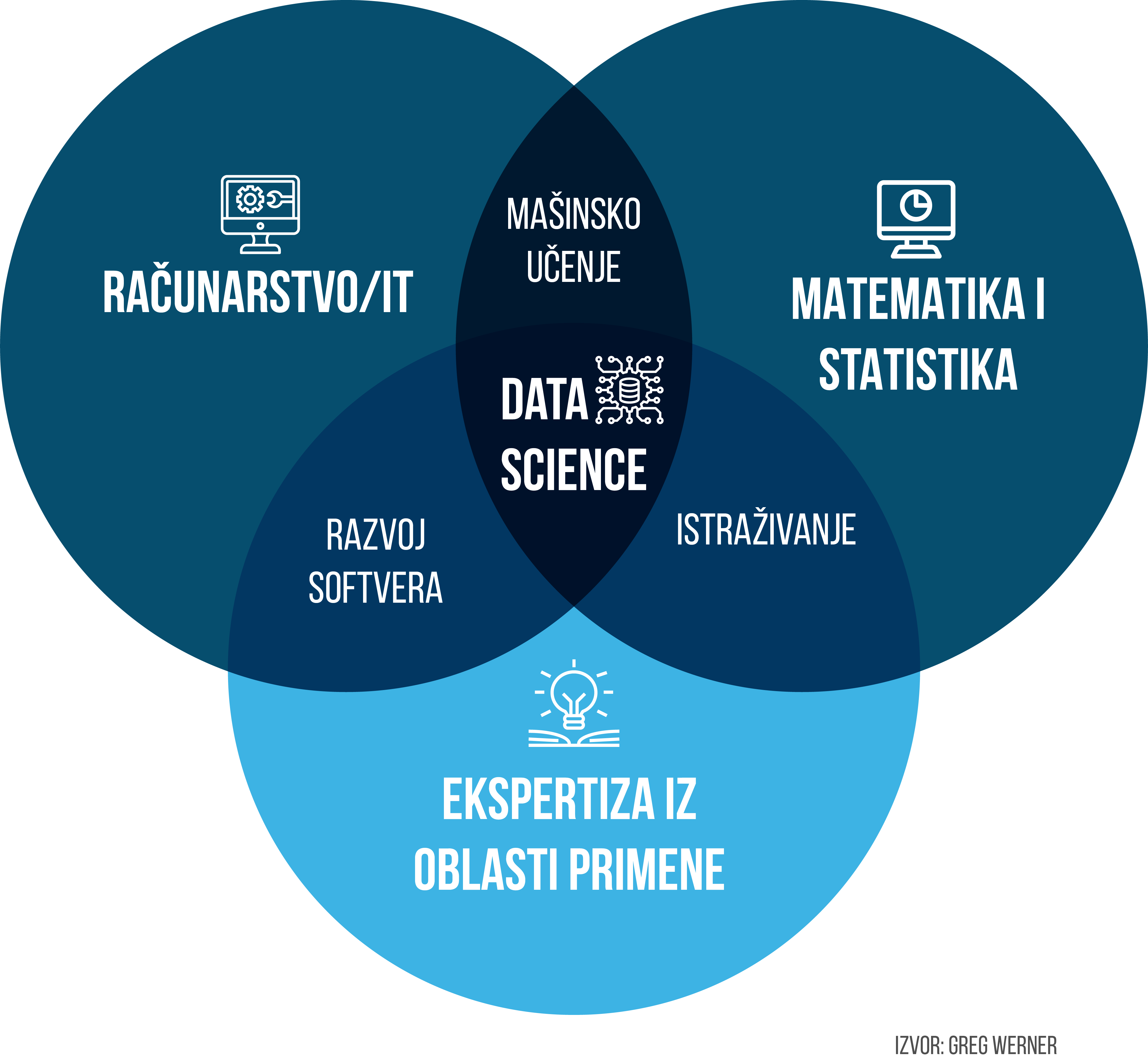
Иако не постоји општеприхваћена дефиниција, према Инвестопедији „наука заснована на подацима (data science) користи велике податке и машинско учење за интерпретацију података у циљу доношења одлука“. Наука заснована на подацима захтева експертизу из различитих области, пре свега из домена струке из које долазе подаци, вештачке интелигенције, статистике и рачунарства, али и шире од тога, математике, машинског учења, вештине комуникације, визуализације података.
„Hi, I’m Siri, your virtul assistant“
За науку засновану на подацима од посебног значаја је развој вештачке интелигенције. Вештачка интелигенција бави се креирањем паметних машина способних да извршавају задатке који захтевају људску интелигенцију. Алгоритми чије се перформансе унапређују све већом изложеношћу великој количини података припадају области машинског учења, која је подскуп вештачке интелигенције. У оквиру машинског учења, посебно се издвајају вишеслојне неуралне мреже које уче из велике количине података. Овај подскуп алгоритама машинског учења назива се дубоко учење (deep learning). Методе дубоког учења доживеле су убрзан развој у последњих 10 година, на шта је утицала велика количина података са којом располажемо, а која је потребна за учење неуралних мрежа.

Примена неуралних мрежа данас је разноврсна, и омогућава развој многих технолошких иновација. Један од раних успешних подухвата који илуструје могућности неуралних мрежа је AlphaGo, први рачунарски програм који је победио професионалног Gо играча, први који је победио Gо светског првака и вероватно је најјачи Gо играч у историји. Gо је игра на табли за два играча која води порекло из Кине и изузетно је комплексна. Постоји 10×170 различитих конфигурација табле, што је чини много комплекснијом игром од шаха.
Захваљујући и обради природног језика (Natural Language Processing Language), данас машине око нас могу разговарати са нама, на нашем језику.
Рад личних рачунарских асистената (Alexa, Siri, Cortana) који не само да разумеју наш језик, већ одговарају и извршавају додељене задатке, базиран је на методама дубоког учења.
Претња од погрешног закључка
Методе дубоког учења имају велики потенцијал у примени у медицини, посебно у дијагностици и прогнози болести. Поред тога што методе машинског учења узимају у обзир тренутно стање пацијента и разне врсте података током времена везане за њега, неуралне мреже стављају тог пацијента у корелацију са групом других пацијената који имају одређене сличности и на бази свих тих података дају предлоге за дијагностику.
Разлог због ког методе дубоког учења нису заживеле у потпуности у клиничкој пракси лежи у великој комплексности ових метода, због чега оне врло често функционишу као црна кутија која даје резултате, али нисмо увек сигурни зашто и како. Ризик лежи у немогућности да дизајнирамо неуралне мреже на систематски начин, као и недостатак интерпретације резултата, што може да доведе до опасности уколико дође до фаталне грешке. Наиме, постоје систематски начини додавања шума у слику на које је могуће збунити неуралну мрежу да произведе погрешан закључак. Један од примера када је безбедност од великог значаја је аутоматизација вожње код самовозећих аутомобила.
Али Рахими из Google-а је током свог предавања 2017. године на конференцији посвећеној машинском учењу, НИПС 2017, изјавио да је дубоко учење постало алхемија и да се често осећа као да користи ванземаљску технологију, добивши овације од публике. То само илуструје изазове са којима се програмери и инжењери сусрећу при раду са неуралним мрежама.
„Интервенција“ математике
Иако методе дубоког учења показују импресивне резултате, математичка теорија која стоји иза ових метода је и даље сиромашна. Зашто неуралне мреже уопште функционишу, како превазићи нестабилности и задржати добре перформансе, само су нека од отворених питања у области дубоког учења на чијем решавању раде многи математички тимови. Током 2018. и 2019. године неколико иницијатива је покренуто од стране математичке заједнице са циљем да дају математичко и теоријско разумевање метода дубоког учења. Међу њима се издвајају иницијативе SIAM-а (Society for Industrial and Applied Mathematics siam.org), као што су нови научни часопис основан 2018. године SIAM Journalon Mathematics of Data Science SIMODS и научна конференција SIAM Conference on Mathematics of Data Science чије је прво издање било планирано за мај 2020, а због проглашене епидемије значајан број најављених предавања је одржано онлајн.
Док нас ка будућности базираној на хуманоидним роботима и вештачкој интелигенцији крупним корацима воде инжењери и истраживачи вођени својом радозналошћу и иновативношћу, као и компаније вођене жељом за профитом, на математичкој заједници је да понуди теоријску основу за развој ових метода, чиме ћемо стећи много бољу контролу, стабилност и безбедност над процесима на којима градимо будућност човечанства.
Поменуте иницијативе пружају наду да ће развој технологија у блиској будућности бити уоквирен солидном математичком подлогом која би требало да пружи сигурност у резултате вештачке интелигенције и анализе података који се прикупљају у огромним количинама сваке секунде. У супротном, врло лако може да нам се деси да дођемо у ситуацију да морамо да доказујемо да нисмо ми на снимку камере, и да је то резултат незадовољавајуће тачности софтвера за препознавање лица. А у многим применама, једина задовољавајућа тачност би била стопостотна.

О аутору: Наташа Ћировић је ванредни професор на Електротехничком факултету Универзитета у Београду. Докторирала је на Математичком факултету 2012. године. Бави се применом математичких метода у области класификације података, оптимизације избора обележја, теоријом фиксне тачке на фази-метричким и вероватносним просторима, као и применом нумеричких метода на решавање инжењерских проблема.
Ангажована је на активностима Пословно-технолошког инкубатора техничких факултета Београд БИТФ од оснивања, посебно у реализацији и координацији пројеката за подстицање развоја нових стартап тимова, комерцијализацију иновација и резултата научно-истраживачког рада, те оснивања нових стартуп компанија у области високих технологија.